



🤖 Disparità di trattamento - Legge Zero #81
Negli USA sono arrivate le prime due pronunce giudiziarie nelle cause promosse dagli artisti contro i provider di IA per violazione del copyright. Spoiler: sono favorevoli alle aziende tech.


🧠 Il paradosso della creatività
Conoscete i Velvet Sundown?
Forse no. Eppure, se utilizzate le piattaforme di streaming per ascoltare musica, potreste - senza volerlo - aver ascoltato un loro brano. Sono la “band” rivelazione del momento su Spotify, hanno esordito a giugno e contano già più di un milione di ascoltatori. Niente male se considerate che la band non esiste, immagini e canzoni sono realizzate con l’intelligenza artificiale.
In meno di un mese, i Velvet Sundown hanno pubblicato due album (“Floating On Echoes” e “Dust and Silence”) e un terzo è in arrivo. Canzoni rock dal sound non originale, gradevoli ma insipide al punto che, se ascoltate di fila, rivelano chiaramente la loro origine sintetica. Eppure, infilate in centinaia di playlist degli utenti, queste tracce hanno ottenuto un successo virale misterioso, forse aiutato da qualche spintarella algoritmica o da furbi stratagemmi di marketing non propriamente trasparenti.
Su Spotify il profilo appare addirittura come “Artista verificato” sulla piattaforma e questo può aver tratto qualcuno in inganno. Su Instagram il gruppo posta foto festose, peccato che gli occhi troppo simmetrici e alcuni dettagli tradiscano immediatamente la mano di Midjourney o ChatGPT. Insomma, i Velvet Sundown sono un gruppo deepfake.
Spotify, però, non sembra farsi troppi problemi: accetta tranquillamente musica generata da IA e non richiede agli artisti di dichiarare se un brano è stato creato con l’aiuto dell’intelligenza artificiale. La trasparenza è un optional, almeno per ora.
Piattaforme concorrenti come Deezer hanno scelto invece una linea più chiara: hanno già “bollato” i Velvet Sundown con l’avviso che “alcune tracce di questo album potrebbero essere state create con intelligenza artificiale”. Deezer vanta filtri capaci di rilevare musica 100% generata dai modelli IA più diffusi - come Suno e Udio - e ha già annunciato che lo farà per qualsiasi altro tool che dovesse emergere.
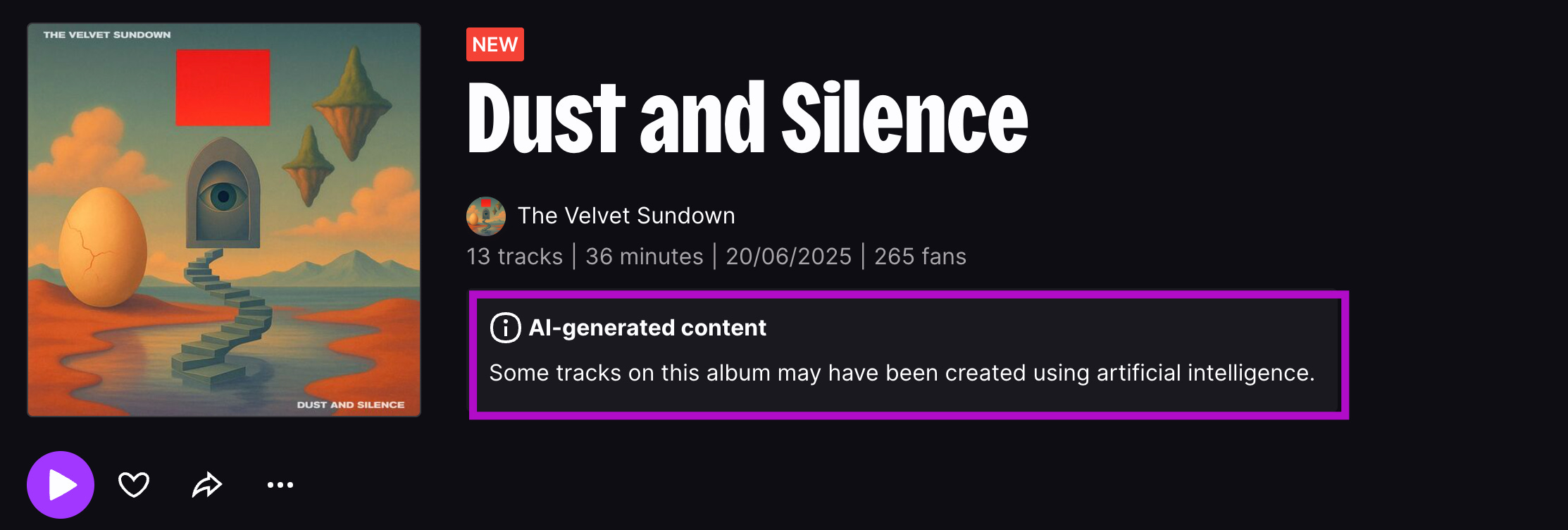
Invece, anche dopo che questa vicenda è diventata mediatica, Spotify e Apple Music per ora tacciono: nessuna etichetta “IA” sugli album dei Velvet Sundown. Anzi, inizialmente sulla bio presente nella pagina Spotify della band campeggiava addirittura una recensione positiva attribuita alla nota rivista Billboard (ovviamente mai pubblicata), riferimento rimosso in fretta dopo che qualcuno l’ha notato.
Adesso, sulla pagina Spotify della band - i cui creatori stanno promuovendo il prossimo album che esce tra una settimana - campeggia questa più onesta descrizione:
The Velvet Sundown è un progetto musicale sintetico guidato dalla creatività umana ma composto, cantato e visualizzato con il supporto dell’intelligenza artificiale.
Non è un trucco: è uno specchio. Una provocazione artistica continua, ideata per mettere in discussione i confini dell’autorialità, dell’identità e del futuro stesso della musica nell’era dell’IA.
Tutti i personaggi, le storie, la musica, le voci e i testi sono creazioni originali generate attraverso strumenti di intelligenza artificiale impiegati come mezzi espressivi. Qualsiasi somiglianza con luoghi, eventi o persone reali - vive o defunte - è puramente casuale e non intenzionale.
Non del tutto umano. Non del tutto macchina. Il progetto The Velvet Sundown esiste da qualche parte lì in mezzo.
Insomma, un po’ per scelta e un po’ per svista, Spotify ha permesso a un gruppo fittizio di spacciarsi per vero e di proliferare senza etichette. Almeno per ora (se siete curiosi, potete ascoltarli qui sotto).
Artisti vs. IA: le prime sentenze
Attenzione: i Velvet Sundown sono solo la punta dell’iceberg. L’IA generativa sta invadendo anche la musica, strumenti come Suno e Udio permettono a chiunque di comporre brani in pochi click, clonando stili e mixando generi. Questo vuol dire che siamo già circondati dalla musica sintetica: secondo dati recenti, su Deezer vengono caricati circa 20.000 brani completamente IA al giorno, pari al 18% di tutti gli upload sulla piattaforma. Un’inchiesta di Music Business Worldwide ha individuato 13 “artisti” interamente IA su Spotify (come i The Velvet Sundown) che totalizzano oltre 4 milioni di ascoltatori mensili. Se vi sembrano numeri bassi, pensate che la startup Boomy con il suo tool ha consentito agli utenti di creare con l’IA qualcosa come 14,4 milioni di canzoni dal 2019 al 2023, l’equivalente del 13,7% della musica pubblicata a livello mondiale in quel periodo. Ed era prima del boom dell’IA generativa.
Ovviamente, è una questione di cui si sta parlando nei tribunali di tutto il mondo, specialmente nelle controversie in cui si dibatte dell’addestramento delle IA con le opere di artisti umani, addestramento che spesso è avvenuto senza riconoscere alcun compenso agli artisti e, quasi sempre, senza la loro autorizzazione. Ne abbiamo dato conto più volte in LeggeZero, a partire dall’ormai celeberrima causa avviata dal New York Times contro OpenAI, si è aperta una battaglia tra i provider di IA e i detentori dei diritti che ha uno dei suoi fronti più importanti nelle controversie legali attivate dalle case discografiche contro le piattaforme che consentono di generare musica e canzoni.
Ora però, a due anni e mezzo dal lancio di ChatGPT, ci troviamo in una fase cruciale di questo scontro. Nei giorni scorsi, due giudici della California si sono espressi su altrettanti casi simbolici riguardanti l’IA e il copyright. E come vedremo, hanno aperto la strada a interpretazioni del fair use che per ora sembrano avallare lo “sfruttamento legale” di intere biblioteche da parte delle IA (pur con qualche avvertimento, e limite, importante).
Il primo verdetto USA rilevante sul rapporto tra addestramento di IA generativa e copyright è arrivato il 23 giugno 2025 dal tribunale federale della California. Il caso era stato promosso da tre autori che avevano citato in giudizio Anthropic – la società creatrice dell’LLM Claude – accusandola di aver usato milioni di libri coperti da copyright per addestrare i suoi modelli. Come? Un po’ comprandone delle copie (fin qui, nulla di strano), un po’ scaricandoli da fonti pirata (meno bene), e addirittura acquistando libri cartacei per poi scannerizzarli e creare un archivio digitale interno (quasi un Google Books fatto in casa).

Il tribunale californiano ha affermato alcuni importanti principi, stabilendo che:
l’uso di opere protette dal copyright è legittimo per il training di LLM: viene riconosciuto il fair use in quanto l’uso di Anthropic sarebbe stato “altamente trasformativo”. Secondo il Giudice, come qualsiasi lettore che aspira a diventare scrittore, i modelli linguistici di Anthropic sono stati addestrati su opere non per replicarle o sostituirle, ma per creare qualcosa di diverso. A seguito di tale addestramento, gli autori non hanno dimostrato che l’IA riproducesse passaggi sostanziali dei libri originali, e quindi - secondo il Tribunale - l’attività degli sviluppatori sarebbe stata finalizzata solo all'apprendimento statistico del linguaggio da parte del modello.
è legittima la digitalizzazione di libri acquistati (ai fini dell’addestramento): in tal caso si è trattato di un mero uso interno, paragonabile a un cambiamento di formato. Se avviene senza alcun tipo di diffusione esterna, la trasformazione da versione cartacea a digitale, con distruzione del cartaceo, è considerata fair use, in linea con precedenti giurisprudenziali (come quello che anni fa riguardò Google Books);
è illegittimo il download e la conservazione di copie pirata: in questo caso non è stato riconosciuto il fair use, in quanto la pirateria non può essere legittimata ex post per finalità innovative. Anthropic ha scaricato oltre 7 milioni di libri da LibGen, Books3 e PiLiMi, conservandoli per i propri scopi. Questo tipo di copia massiva e permanente è stato ritenuto non coperto da fair use e, per questa ragione, è stato disposto un processo separato per determinare danni che potrebbero essere quantificati in miliardi di dollari.
Nel complesso, però, la pronuncia segna un punto a favore dei provider: se le copie sono legittimamente acquisite, l’addestramento delle IA è lecito.
Il secondo provvedimento - arrivato appena due giorni dopo quello relativo ad Anthropic - è stato depositato nel processo intentato da tredici autori (tra cui lo scrittore fantasy Richard Kadrey) contro Meta per l’addestramento del modello LLaMA sui loro libri. Qui la situazione di fatto era analoga: Meta, come Anthropic, aveva utilizzato un gigantesco dataset testuale per addestrare i suoi LLM e tra le fonti figuravano milioni di libri ottenuti in vario modo (si parla di 7,5 milioni di libri piratati, oltre a 81 milioni di articoli accademici, provenienti da set di dati “open”). Gli autori lamentavano la violazione del loro copyright, sostenendo che Meta avesse copiato le loro opere senza autorizzazione - né compenso - per costruire un prodotto commerciale.
Già in una fase preliminare il Tribunale aveva mostrato scetticismo, sostenendo che gli autori non avessero dimostrato dove e come l’output di LLaMA violasse concretamente i loro diritti. Dopo aver concesso loro di riformulare la denuncia, il 25 giugno 2025 il giudice ha emesso una nuova ordinanza che respinge il ricorso degli autori. In sostanza, ha dato ragione a Meta, ma la sua decisione contiene avvertenze importanti e una logica un po’ diversa dal caso Anthropic.
Cominciamo dalla parte comune tra le due pronunce: anche questa pronuncia ritiene che l’uso dei libri da parte di Meta sia “altamente trasformativo”. Cosa significa? Che l’uso fatto dal provider ha uno scopo e una natura diversi rispetto all’opera originale. I libri sono stati utilizzati non per essere ripubblicati o sostituire i romanzi sul mercato, ma per insegnare al modello a generare testo nuovo. Inoltre, gli autori non sono riusciti a dimostrare un danno concreto: non hanno portato evidenze di brani generati dall’IA che riproducessero pedissequamente parti dei loro libri, né hanno provato che l’IA di Meta abbia creato un surrogato che tolga mercato ai loro lavori (ad esempio, nessuna “versione sintetica” dei romanzi che rubi lettori, né perdite di opportunità commerciali). Va detto che sono prove difficili da fornire e che, comunque, è indubbio che se ascolto una canzone dei The Velvet Sundown non ascolterò una canzone (scritta e suonata da umani) degli Eagles o degli Allman Brothers.
Il giudice però è consapevole che questa conclusione suona un po’ “distante dalla realtà” (parole sue) e lo attribuisce alla debolezza delle prove fornite dagli autori. Traduzione: avete sbagliato la strategia processuale. E infatti precisa: “Questa sentenza non sta affermando che l’uso di materiali protetti da parte di Meta per addestrare i suoi modelli linguistici sia legale”. Si applica solo a questo caso specifico, in cui gli autori non hanno usato gli argomenti giusti.
Pur respingendo il ricorso, il giudice ha comunque affermato che addestrare le IA su vaste collezioni di opere umane potrebbe generare un rischio sistemico: “addestrando modelli generativi con opere protette, le aziende creano qualcosa che spesso andrà a minare drasticamente il mercato di quelle opere, e dunque l’incentivo per gli esseri umani a creare nel modo tradizionale”. Tradotto: un modello generativo potrebbe “inondare il mercato” con innumerevoli testi, immagini, canzoni in pochissimo tempo, saturando l’offerta e deprezzando il lavoro originale degli umani.
Oltre al danno, la beffa
I precedenti che abbiamo citato sono importanti perché vengono dagli USA (sede dei provider di IA più importanti) e perché in quell’ordinamento sono vincolanti per futuri giudizi. In ogni caso, vale la pena sottolineare che siamo ancora lontani dalla soluzione definitiva, perché le pronunce verranno sicuramente appellate e, nel frattempo, ci saranno altre decisioni di tribunali federali.
Nel frattempo, commentando proprio queste importanti pronunce - per ora favorevoli ai provider IA - il giornalista e scrittore Alexander Hurst ha scritto un editoriale sul Guardian in cui ha esposto un paradosso.
Hurst racconta la sua esperienza: sta scrivendo un libro e avrebbe voluto aprirlo citando un verso della canzone Bloodbuzz Ohio dei The National “Devo ancora dei soldi ai soldi che devo”. Problema: il suo editore è contrario perché anche solo 12 parole del testo di canzone possono scatenare le contestazioni della casa discografica. E ottenere una licenza di quel breve estratto potrebbe costare una fortuna. Quindi, niente citazione.
Fin qui nulla di nuovo: citare brani di canzoni in opere letterarie può essere un percorso a ostacoli, spesso scoraggiato dalle case discografiche. Ma ecco l’assurdo: un provider di IA, quotato miliardi di dollari, potrebbe forse utilizzare l’intera discografia dei The National (di Eminem e di chiunque) per addestrare il proprio modello, magari generando versi praticamente identici su richiesta degli utenti. Hurst immagina un prompt: “scrivi un rap nello stile di Eminem sulla perdita di denaro, ispirandoti a Bloodbuzz Ohio”. Cosa otterrebbe l’utente? Magari una strofa come:
Devo ancora dei soldi ai soldi che devo, ma sputo oro dalla gola quando rappo...
Un testo che include pari pari il verso dei The National, proseguendo con rime alla Eminem. Ebbene – sottolinea Hurst – secondo alcune recenti sentenze USA, tutto ciò sarebbe considerato “fair use” e non costituirebbe affatto violazione di copyright, senza versare diritti d’autore ad alcuno. Il paradosso indicato da Hurst è questo: un comune scrittore non può riportare dodici parole di una canzone in un libro, mentre l’IA può rigurgitare versi interi in un nanosecondo, dopo aver assimilato tutta la musica esistente, e per la legge americana pare andar bene.
L’autore lo definisce un ribaltamento dello spirito del diritto d’autore, che finirebbe per favorire i grandi attori tech rispetto ai comuni creatori umani.
Vista da questa prospettiva, la partita tra artisti e IA sembra ancora più in salita se non arriveranno risposte tecnologiche e normative.
💊 IA in pillole
Il 1º luglio 2025 la società Cloudflare, che gestisce l’infrastruttura di un’enorme parte dei siti web mondiali, ha annunciato una svolta: bloccherà di default i crawler delle IA, impedendo loro di accedere ai contenuti online senza permesso o compenso. In pratica, chi crea un nuovo sito con Cloudflare trova già attiva l’opzione “no AI scrapers”. Invece, per i clienti esistenti è disponibile un semplice tasto per dire alle IA generative di stare alla larga dalle proprie pagine. Non solo: Cloudflare sta introducendo un modello “Pay Per Crawl”, attualmente in beta per alcuni grandi editori, che permetterà ai siti di fissare un prezzo per ogni bot di IA che vuole scansionare i loro contenuti. I provider di IA dovranno decidere: pagare per accedere ai dati di quel sito oppure rinunciare. Siamo di fronte a un cambio di paradigma: l’obiettivo è quello di dare ai creatori un vero controllo sui propri contenuti, costruendo un modello economico che funzioni per tutti. Le conseguenze potrebbero essere importanti. Da Cloudflare passa una parte importante del traffico web: questo significa che i dataset di addestramento usati dagli sviluppatori potrebbero ridursi notevolmente, in quanto il bottino del webscraping sarebbe notevolmente più magro rispetto al passato. Questo potrebbe spingere i provider a trattative finalizzate a stipulare partnership e accordi di licenza. Certo, restano tanti interrogativi. Basterà Cloudflare? Ci saranno standard condivisi? Davvero i provider accetteranno di pagare? In ogni caso una cosa è certa: le soluzioni tecnologiche - per ora - sono arrivate più velocemente (e forse efficacemente) di quelle normative.
Il tema del copyright nell’era dell’IA è caldo anche in Europa. Nei giorni scorsi - nell’ambito dei lavori del Parlamento Europeo - è stata pubblicata la prima bozza di un report dal titolo "Copyright and generative artificial intelligence – opportunities and challenges", a cura del parlamentare Axel Voss. Si tratta di un documento che indicherà alla Commissione UE dove AI Act, Data Act e direttiva Copyright stanno fallendo.
La relazione parte da un presupposto: senza contenuti protetti dal diritto d’autore non c'è qualità nei modelli IA, ma senza regole sull’uso dei contenuti protetti per l’addestramento delle IA non c'è futuro per i creativi europei. Il documento quindi propone:
- trasparenza integrale sui dati di addestramento (fino ai singoli file) senza la quale dovrebbe scattare una presunzione assoluta di uso illecito dei contenuti;
- un registro unico per garantire l’opt-out dei detentori dei diritti;
- l’obbligo per i provider di riconoscere un equo compenso ai titolari dei diritti sui contenuti, quantificato nel 5-7% del fatturato mondiale per i fornitori di modelli IA che usano contenuti protetti.Il testo - che ha il pregio di porre sul tavolo temi da risolvere urgentemente - entra ora nella fase dell’esame parlamentare. Dovrebbe arrivare in plenaria entro l’autunno. Una volta approvato, potrebbe obbligare la Commissione a rispondere entro tre mesi, magari con proposte normative che recepiscano questi suggerimenti.
Ricordate la moratoria di dieci anni sulle leggi dell’IA proposta negli USA? Nei giorni scorsi è stata bocciata con un voto plebiscitario: 99 favorevoli alla sua cancellazione, 1 contrario. Si tratta di una maggioranza (evidentemente) bipartisan che ha respinto la linea del “laissez-faire” sostenuta da parte del mondo tech, riconoscendo che servono regole chiare per tutelare persone, imprese e democrazia.
Perché è importante?
1️⃣ Finisce il mito che “regolamentare l’IA soffoca l’innovazione”: persino il Paese della Silicon Valley - alla prova dei fatti - sceglie la via della regolazione.
2️⃣ Assisteremo a una proliferazione di norme "made in USA": gli stati americani (da New York al Colorado) continueranno a varare norme su deepfake, tutela dei minori online, addestramento dei modelli, diritti dei lavoratori e sicurezza dei veicoli autonomi.
3️⃣ È un messaggio per Europa e Italia: la domanda non è più se regolamentare, ma come farlo in modo efficace, adeguato e tempestivo. Insomma, fuori dalla retorica, è arrivato il momento di confrontarsi sul contenuto e sulle caratteristiche delle regole dell'IA.
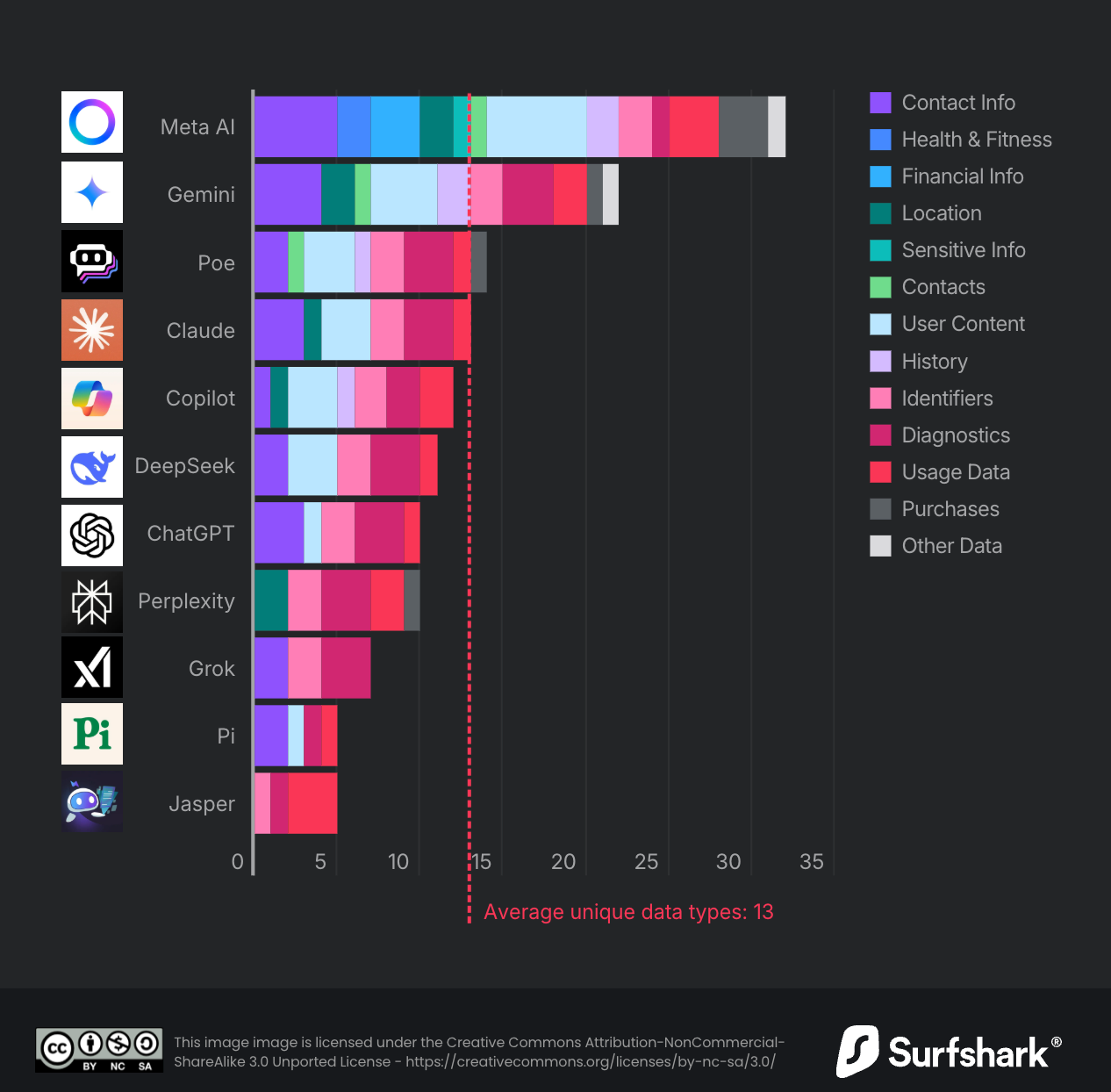
Vi siete mai chiesti quali sono i dati che raccolgono i chatbot di IA che utilizzate? Se la risposta è positiva, questo studio di Surfshark (un importante provider di VPN) fa al caso vostro: analizza le pratiche di raccolta dati dei 10 principali chatbot IA disponibili su Apple Store, rivelando differenze significative nel trattamento della privacy degli utenti. Ecco alcuni dati interessanti:
Meta AI è il chatbot più affamato, raccoglie ben 32 tipi di dati diversi (compresi quelli finanziari, sanitari e l’orientamento sessuale);
Google Gemini si posiziona al secondo posto con 22 tipi di dati raccolti, inclusa la posizione dell'utente. Raccoglie anche informazioni di contatto, cronologia di navigazione, contenuti e contatti del telefono;
ChatGPT risulta uno dei più “discreti”, raccogliendo solo 10 tipi di dati. Non utilizza tracking o pubblicità di terze parti e offre chat temporanee che vengono cancellate automaticamente dopo 30 giorni;
DeepSeek tiene traccia di 11 tipi di dati, ma conserva le informazioni su server in Cina e ha già subito una violazione che ha esposto oltre 1 milione di record;
in generale, il 45% delle app raccoglie la posizione degli utenti e il 30% circa traccia gli utenti per scopi pubblicitari.

La ricerca evidenzia come non tutti i chatbot IA siano uguali in termini di privacy. La raccomandazione è quella di leggere sempre le privacy policy e scegliere consapevolmente quale strumento utilizzare in base al proprio livello di comfort con la condivisione dei dati. Oppure, se le informative vi sembrano troppo lunghe e difficili, seguiteci. Noi - periodicamente - vi aggiorneremo sulla bulimia dei dati dei chatbot.
😂 IA Meme
Artisti vs. Provider IA: non è solo una questione di soldi.

😂 IA Meme … che non lo erano
Il 28 giugno scorso, a Pechino, si è svolto il primo match di calcio completamente autonomo tra robot umanoidi della storia. La partita è diventata immediatamente virale, ma forse non per i motivi che gli organizzatori speravano.
I robot T1 da 30kg si sono comportati come giocatori ubriachi che inciampano sul campo, cadendo ripetutamente e scontrandosi tra loro. Il momento più esilarante è arrivato quando due robot hanno dovuto essere portati via dal campo in barella, dettaglio che ha scatenato molta ilarità.
Ma dietro le risate si nasconde una rivoluzione tecnologica. Questi robot hanno giocato senza alcun intervento umano, utilizzando l’IA per prendere decisioni in tempo reale. Per la prima volta nella storia, macchine completamente autonome hanno coordinato strategie di gioco, passaggi e movimenti sul campo.
Il paradosso è stridente: quella che sembra una dimostrazione fallimentare è in realtà una pietra miliare tecnologica. Queste cadute goffe rappresentano i primi passi verso un futuro in cui l'autonomia robotica sarà realtà, anche nello sport.
Non sempre la rivoluzione è elegante, a volte inciampa, ma continua ad andare avanti più veloce di quanto pensiamo.
📢 🚨 Breaking news
Nonostante le richieste provenienti da più parti, non ci sarà nessuna proroga per l’adeguamento all’AI Act, lo ha detto venerdì - in conferenza stampa - Thomas Regnier, portavoce della Commissione UE:
Voglio essere il più chiaro possibile, non c'è modo di fermare il tempo. Non ci sarà un periodo di tolleranza. Non ci sarà nessuna pausa.
Avanti veloci con l’adeguamento, quindi. Tutti, imprese e istituzioni.
📣 Eventi

🙏 Grazie per averci letto!
Per ora è tutto, torniamo la prossima settimana. Se la newsletter ti è piaciuta, sostienici: metti like, commenta o fai girare!