



🤖 Abbiamo esaurito i dati – Legge Zero #57
Secondo Elon Musk, nel 2024 le IA hanno già esaurito tutti i dati disponibili per l'addestramento. Ma i provider hanno bisogno di molti più dati per creare modelli e sistemi ancora più efficienti.


🧠 Le IA sono affamate (di conoscenza)
Leggo fantascienza per immaginare cosa potrebbe cambiare e letteratura antica per capire cosa non cambia.
Lo ha twittato qualche giorno fa, David Holz - fondatore di MidJourney (sistema di IA per generare immagini da testo) - sintetizzando un approccio interessante: usare l'immaginazione per sondare il futuro e la saggezza per ancorarsi al passato.
Ed effettivamente, molto di quello che sta accadendo nel settore dell’IA sembra tratto da film di fantascienza (ne abbiamo parlato in LeggeZero #56) o serie distopiche, costringendoci a fare i conti con un futuro che sembrava molto lontano e che invece è già arrivato.
Negli anni scorsi, ad esempio, si è diffusa la consapevolezza secondo cui i dati erano ‘il nuovo petrolio’, facendo comprendere l’importanza dell’informazione nell’economia della conoscenza per la produzione di beni e servizi innovativi (come l’addestramento di modelli e sistemi di intelligenza artificiale). Eppure non abbiamo avuto neanche il tempo di comprenderlo - e regolamentarlo efficacemente - che i dati sarebbero già ‘esauriti’.
Nel corso di una recente intervista condotta da Mark Penn, Elon Musk ha dichiarato siamo già arrivati al punto in cui le aziende di IA hanno utilizzato tutti i dati disponibili per addestrare i loro modelli, esaurendo di fatto la conoscenza umana.
Si tratta di un problema non da poco visto che i provider hanno bisogno di sempre maggiori quantità di dati per rendere i loro sistemi ancora più performanti ed efficienti. Infatti, a differenza degli esseri umani che possono imparare concetti complessi da pochi esempi, le attuali IA hanno bisogno di tantissimi dati per comprendere nozioni e sfumature. È come se dovessero vedere migliaia di volte lo stesso concetto per interiorizzarlo veramente.
È questo il motivo per cui hanno ingaggiato la guerra dello scraping, rastrellando tutte le informazioni presenti sul web, esponendosi anche a contenzioso e contestazioni da parte delle autorità (specialmente europee). OpenAI, ad esempio, ha ammesso pubblicamente che sarebbe impossibile sviluppare strumenti come ChatGPT senza usare per l’addestramento materiale protetto da copyright. Inoltre, nell’ambito di uno dei tanti contenziosi dagli autori contro i provider di IA è addirittura emerso che sarebbe stato direttamente Mark Zuckerberg ad autorizzare il team di Meta a usare opere protette da copyright per l’addestramento del modello. I dati sono troppo importanti e la guerra al modello migliore la vincerà chi avrà più informazioni per l’addestramento.
L’allarme di Musk è quindi assai realistico. Secondo questo paper, pubblicato nel 2022, i dati sarebbero stati esauriti a partire dal 2026, ma è probabile che l’accelerazione dei progressi dei provider - e la corsa a modelli sempre migliori - abbia anticipato questa data.
Come fare fronte a questa situazione? Musk non ha molti dubbi: la soluzione è quella di ricorrere a dati sintetici, cioè dati artificiali che simulano il mondo reale. Insomma dati creati da IA per addestrare IA. Tuttavia, secondo alcuni esperti, l’eccessiva dipendenza dei modelli da dati sintetici potrebbe peggiorare progressivamente la qualità delle IA con il rischio, ad esempio, di maggiori allucinazioni.
Un’altra soluzione potrebbe essere quella di utilizzare dati non pubblici (o fin qui non utilizzati), come ad esempio libri non presenti online oppure i dati dei social media. Ma questa pratica passa per l’ottenimento di licenze e consensi dai titolari dei diritti. Non deve stupirci quindi, ad esempio, che OpenAI e Google stiano già pagando i creator per i loro video non pubblicati, con compensi tra 1 e i 4 dollari per minuto (ne parla Bloomberg qui).
Le IA hanno finito i nostri dati e noi stiamo lavorando per produrne altri, per loro e non per noi.
🔊 Un vocale da… Giuseppe Vaciago (Ordine degli Avvocati di Milano)
Come si può guidare l’uso dell’IA negli studi professionali in modo che sia rispettoso delle leggi e delle regole deontologiche? Cosa possono fare gli ordini professionali?
Nel vocale di questa settimana ce ne parla il coordinatore del Tavolo IA e Giustizia dell’Ordine degli Avvocati di Milano, illustrandoci il progetto Horos - dal greco ‘confine’ - che ha l’obiettivo di delineare i confini dell’IA in ambito forense e di proporre iniziative strutturate di alfabetizzazione.
Per saperne di più sulla ‘carta dei principi’, continuate a leggere la newsletter.
📰 Apple sospende la funzionalità ‘Intelligence’ (ma solo per le notizie)
Ricordate quando in Legge Zero #46 vi abbiamo parlato dell'iPhone che - riassumendo i messaggi ricevuti da un utente - gli aveva comunicato che la sua ragazza l’aveva lasciato? È stato uno dei primi “effetti indesiderati” di Intelligence, la funzionalità IA di Apple che consente di riassumere notifiche o messaggi, e che vorrebbe aiutare gli utenti a gestire meglio le informazioni ricevute. Tuttavia, sembra che la stessa tecnologia capace di sintetizzare intere conversazioni di una coppia in crisi in un’unica, gelida, notifica sia anche in grado di fare gravi errori quando riassume le notizie di attualità.
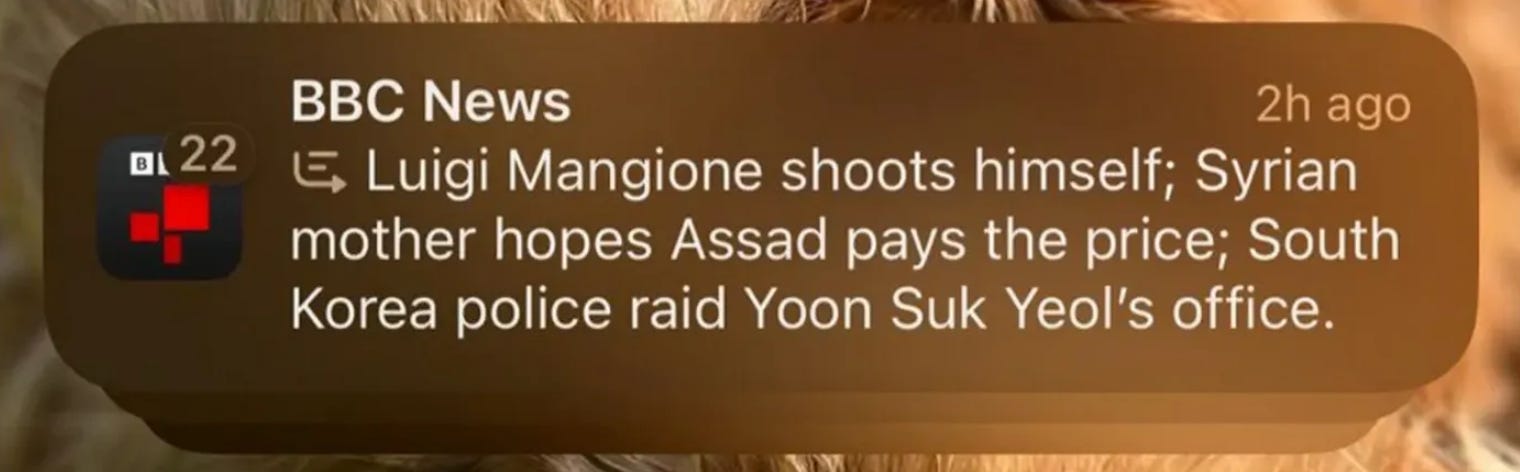
Nel corso delle ultime settimane si sono moltiplicati gli esempi di riassunti generati dall’IA che non erano fedeli alle notizie pubblicate dagli organi di informazione (nonostante alla notifica venisse accostato il logo della testata). Ad esempio, gli utenti hanno letto una notifica apparentemente proveniente dalla BBC in cui si diceva che il giocatore di freccette Luke Littler aveva vinto il campionato mondiale, ma prima che si disputasse la finale. Apparentemente, l’errore è derivato da un’errata interpretazione da parte dell’IA della notizia della vittoria in semifinale.Ma non è l’unico caso: l’IA ha inventato che il tennista Nadal avrebbe fatto coming out e che Luigi Mangione - in carcere per l’omicidio di Brian Thompson - si sarebbe suicidato.
Questi errori hanno destato molta preoccupazione sul contributo che l’IA può dare alla propagazione delle fake news, minando la fiducia del pubblico nei confronti dei mezzi di informazione (spingendo addirittura la BBC a protestare formalmente).
Evidentemente, la paura di errori più gravi e di contestazioni legali ha spinto Apple a sospendere la funzione intelligence - ma solo per le notizie, non per i messaggi - finché non saranno risolti questi problemi e l’IA non sarà affidabile nei riassunti. Inoltre, da ora in poi tutti i riassunti generati dall’intelligenza artificiale saranno riportati in corsivo per rendere più facile distinguerli dalle normali notifiche. Inoltre, Apple inserirà un disclaimer che affermerà che questa funzionalità può commettere errori.
Sarà sufficiente per evitare contenziosi e responsabilità?
📰 Il Regno Unito 🇬🇧 presenta il suo action plan 2025-2030 in materia di IA
Qualche settimana fa, l’Università di Stanford ha pubblicato il Gobal Vibrancy Tool, report in cui ha dato le pagelle ai diversi Stati in materia di IA (ne abbiamo scritto in LeggeZero #51). Al primo posto - senza sorprese - gli USA, al secondo la Cina, al terzo il Regno Unito (Italia 22sima).
Nonostante questo lusinghiero risultato, il Governo di Sua Maestà ha deciso di mettere in campo una strategia quinquennale con l’obiettivo di rendere UK il leader mondiale nel settore dell’intelligenza artificiale.
Il Governo ha dapprima incaricato un gruppo di esperti di elaborare una strategia, indicando le priorità (AI Opportunities Action Plan). Nei giorni seguenti alla pubblicazione di questo documento, il premier Keir Starmer ha lanciato un ambizioso piano d'azione per aumentare di 20 volte la potenza di calcolo dell'intelligenza artificiale sotto il controllo pubblico entro il 2030 e impiegare l'intelligenza artificiale in ogni settore della società, dall'individuazione delle buche stradali al supporto nel settore educativo. Si tratta di un documento agile (22 pagine) che potete consultare qui (in inglese).
Il piano d’azione rappresenta un rilevante cambiamento di approccio rispetto al precedente esecutivo inglese che si era concentrato sulla lotta ai rischi “di frontiera” più gravi derivanti dall’intelligenza artificiale, relativi ai pericoli legati alla sicurezza informatica, alla disinformazione e alle armi biologiche.
La strategia UK è importante per almeno due ragioni. Da un lato, è l’esempio di un documento politico strutturato che - pur partendo dalle raccomandazione degli esperti - racchiude un piano industriale, un progetto per la pubblica amministrazione e una pianificazione per l’alfabetizzazione dei cittadini. Dall’altro, perché vuole ribaltare anche la narrativa politica sull’IA: da fonte di rischi per i diritti e libertà delle persone a imperdibile opportunità per l’economia. Si tratta di un mutamento rilevante anche per l’opinione pubblica: secondo un recente sondaggio, gli inglesi sono preoccupati dall’IA (le parole che associano all’IA sono ‘spaventoso’, ‘preoccupato’ e ‘incerto’).
Questo significa che realisticamente dal punto di vista normativo assisteremo all’approvazione di leggi che avranno l’obiettivo di incentivare l’innovazione e non di proteggere le persone dai danni dell’IA. È per questo motivo che gli attivisti per i diritti digitali hanno accolto l’annuncio governativo con molto scetticismo.
⚖️ L’ordine degli avvocati di Milano adotta la prima Carta dei principi 🇮🇹 per l’uso dell’IA in ambito forense
Ne abbiamo parlato nel vocale di questo numero: l’ordine degli Avvocati di Milano ha presentato HOROS, una carta dei principi per l'uso consapevole dei sistemi di intelligenza artificiale in ambito forense, la prima in Italia.
L’obiettivo è fornire indicazioni concrete agli avvocati per integrare l’IA nella propria attività professionale, senza compromettere principi etici, deontologici e rispetto dei diritti fondamentali, ‘facendo sì che l’IA sia messa al servizio della giustizia e non dell’efficienza fine a se stessa’.
Ecco una sintesi del decalogo di Horos.
Principi generali da rispettare quando si usa l’IA: legalità, correttezza, trasparenza, responsabilità, adeguatezza.
Dovere di competenza: l’uso consapevole dell’IA da parte dell’avvocato richiede formazione e costante aggiornamento delle proprie competenze tecnologiche.
Trasparenza nell’uso dell’IA: l’avvocato non solo deve informare il cliente sull’uso dell’IA e del possibile impatto sul servizio legale fornito, ma deve anche saper spiegare come le tecnologie possono fornire un contributo utile e affidabile.
Centralità della decisione umana: l’avvocato deve scegliere le soluzioni adeguate e valutare criticamente e in maniera approfondita i risultati forniti dall’IA.
Protezione dei dati e riservatezza: l’uso dell’IA da parte dell’avvocato deve avvenire nel rispetto delle norme sulla privacy, identificando i rischi per i diritti e le libertà degli interessati.
Sicurezza informatica: l’avvocato deve implementare misure di sicurezza adeguate nell’utilizzo di sistemi di IA e dotarsi di una procedura per la gestione di eventuali incidenti.
Valutazione del rischio: l’utilizzo dei sistemi di IA in ambito forense deve tenere in considerazione i rischi derivanti dalla non accuratezza dei sistemi di IA, dalla presenza di bias o errori e scongiurare le conseguenti possibili discriminazioni.
Diversità e sostenibilità ambientale: l’avvocato è chiamato a verificare che i sistemi di IA garantiscano il rispetto delle diversità e, inoltre, a privilegiare comportamenti e soluzioni tecnologiche sostenibili.
Formazione continua e re-skilling: la formazione continua dell’avvocato e dei suoi collaboratori deve assicurare anche l’aggiornamento e l’approfondimento di competenze tecnologiche, anche al fine di gestire efficacemente i rischi dell’IA.
Tutela del diritto d’autore: l’avvocato ha il dovere di garantire che l’utilizzo di opere protette dal diritto d’autore avvenga in modo lecito, evitando che documenti e banche dati siano utilizzati come dati di input se non consentito dai termini di licenza d’uso.
Un tavolo permanente si occuperà di aggiornare la Carta e monitorare la rapida evoluzione in materia, promuovendo la formazione continua dei professionisti forensi.
È auspicabile che anche altri Ordini seguano l’esempio dei colleghi del foro di Milano, anche nell’ottica di fornire a tutti gli avvocati indicazioni utili a cogliere le opportunità dell’IA, riducendo i rischi.
Il testo della carta dei principi può essere scaricato qui.
⚖️ In California 🇺🇸 entra in vigore una legge per evitare l’uso sistematico dell’IA per rigettare richieste di rimborso delle spese sanitarie
In LeggeZero #39 vi avevamo parlato del fatto che, qualche mese fa, il Governatore della California Gavin Newsom era stato chiamato a ratificare una serie di leggi statali in materia di IA. Tra quelle firmate dal Governatore c’è anche il ‘Physicians Make Decisions Act’ (Senate Bill 1120), entrato in vigore lo scorso 1° gennaio. La legge rappresenta una risposta alla crescente insoddisfazione pubblica per i sempre più frequenti dinieghi di rimborso nel settore delle assicurazioni sanitarie, fenomeno dovuto al sempre più massiccio impiego di sistemi di IA.
Naturalmente, la nuova legge non vieta tout court alle assicurazioni l’utilizzo dell’IA per l’esame delle richieste, ma stabilisce alcuni presìdi affinché l’intervento umano rimanga sempre centrale nel processo decisionale, per quanto automatizzato. In primo luogo, infatti, la norma prevede che gli strumenti di IA non potranno essere utilizzati per negare, ritardare o modificare l’erogazione di servizi e prestazioni ritenuti necessari da un medico o da un professionista sanitario.
Se poi una compagnia assicurativa californiana decidesse di utilizzare comunque tali strumenti, dovrebbe farlo in modo equo, non discriminatorio e, soprattutto, trasparente. Le nuove disposizioni prevedono infatti l’obbligo di informare gli interessati sulle modalità di utilizzo e di supervisione dell’IA.
Inoltre, l’IA dovrà necessariamente tenere conto - nell'esame delle richieste - una lunga lista di informazioni, quali la storia clinica del paziente, le circostanze individuali del soggetto richiedente, le raccomandazioni presentate dal medico curante, nonché ogni altra informazione clinica pertinente.
Il Dipartimento della Sanità della California sarà responsabile della vigilanza sul rispetto della nuova legge, con il supporto di altre autorità statali che avranno il potere di ispezionare gli strumenti di IA utilizzati al fine di valutarne la conformità a quanto prescritto dal Legislatore.
Questa norma è rappresentativa dell’approccio attuale degli Stati Uniti alla regolazione dell’IA: norme dei singoli Stati (non federali) per ambiti molto specifici e settoriali. Questo significa un proliferare di leggi speciali, a differenza dell’UE dove un’unica legge organica (l’AI Act) si applica a tutti i settori, distinguendo diversi scenari di impatto dei sistemi IA sui diritti e libertà delle persone. Al di là delle apparenze, quale si rivelerà l’approccio più agile?
💊 IA in pillole
Sono sempre più i lavoratori che, come noi, usano strumenti di IA nella loro quotidianità. Ma quali sono le domande che un lavoratore (o un sindacalista) dovrebbe fare per comprendere come l’IA viene utilizzata nella propria organizzazione?
Secondo il Comitato Economico e Sociale Europeo (CESE) - che ha elaborato una ‘guida all’IA sul posto di lavoro’ - sono le seguenti:
la mia azienda/amministrazione utilizza sistemi di intelligenza artificiale?
chi ha deciso di implementare un sistema di intelligenza artificiale e perché lo ha fatto? Se il sistema è stato acquistato, chi è il fornitore che lo ha progettato, chi lo ha acquistato all'interno dell'azienda e in base a quali criteri?
a chi è utile il sistema?
a chi può causare danni e per chi comporta svantaggi?
chi è escluso dall’intelligenza artificiale e quanti diritti rischiano di essere persi a causa del suo utilizzo?
come è stata presa la decisione di implementare il sistema, di chi è stata cercata l’opinione e con quale procedura?
chi è il proprietario dei dati, chi ha accesso o diritti d’uso?
gli utenti e i dipendenti sono coinvolti nella progettazione del sistema di IA?
GeoSpy è il servizio fornito dalla società statunitense Graylark Technologies che promette di ridefinire - grazie all’IA - il nostro rapporto con lo spazio urbano e la privacy. L’app consente di identificare i luoghi in cui una foto è stata scattata. La tecnologia è indubbiamente impressionante: sfruttando modelli visivi avanzati, l'app può triangolare la posizione di una foto analizzando dettagli visivi e metadati. Al momento opera in cinque città - San Francisco, New York, Memphis, Berlino e Singapore - offrendo un'accuratezza che apre scenari interessanti per creator, urbanisti, appassionati di fotografia, forze dell’ordine e semplici utenti (potreste conoscere l’indirizzo esatto di una struttura presente su Airbnb prima di prenotarla).
Tuttavia, è proprio questa precisione a sollevare interrogativi importanti. La privacy policy nebulosa lascia spazio a domande cruciali: che fine fanno le immagini caricate? Le persone ritratte nelle foto diventano involontariamente parte di un database di training? È come se stessimo costruendo, click dopo click, una mappa dettagliata non solo dei luoghi, ma anche delle persone che li abitano?
Il paradosso è evidente: più l'app diventa precisa nel suo compito, più sottile diventa il confine tra utilità e sorveglianza. Non stiamo solo mappando spazi, stiamo potenzialmente tracciando movimenti e abitudini di persone ignare (e rendendo più facile ai malintenzionati farlo).
In un'epoca in cui la nostra impronta digitale è già così pervasiva, GeoSpy ci invita a riflettere su quanto siamo disposti a sacrificare in nome dell'innovazione. La vera sfida non sarà tanto perfezionare l'algoritmo, quanto definire i limiti del suo utilizzo.
😂 IA Meme
L’IA ci ucciderà tutti? Le sette fasi della negazione del rischio in questo meme che fa sorridere, ma anche riflettere se guardiamo al dibattito pubblico sull’intelligenza artificiale.
Il rischio non è reale
Abbiamo ancora tempo
Possiamo sempre spegnerla
Non possiamo fermare il progresso
Se non lo facciamo noi, lo farà la Cina
Ecco una soluzione fasulla
È troppo tardi, avreste dovuto dircelo prima!

📚 Consigli di lettura: ‘Gli errori dell’IA sono molto diversi dagli errori umani’ di Bruce Schneier e Nathan Sanders
IEEE Spectrum - la rivista online dell’Institute of Electrical and Electronics Engineers - ha pubblicato un interessante articolo di Bruce Schneier e Nathan Sanders che affronta un tema cruciale per il futuro dell'intelligenza artificiale: la natura peculiare degli errori commessi dai sistemi di IA rispetto a quelli umani.
L'articolo, dal titolo ‘AI Mistakes Are Very Different Than Human Mistakes’, parte da una considerazione fondamentale: l'umanità ha sviluppato nel corso dei millenni sistemi di sicurezza efficaci per gestire gli errori umani, dai controlli incrociati in ambito contabile alla rotazione dei croupier nei casinò. Tuttavia, questi sistemi potrebbero non essere adeguati per gli errori dell'IA, che seguono schemi completamente diversi.
Gli autori evidenziano come gli errori dell'IA, specialmente nei Large Language Models, non siano prevedibili o concentrati in aree specifiche come quelli umani. Un LLM potrebbe essere ugualmente propenso a sbagliare un calcolo matematico o a fare affermazioni surreali come ‘i cavoli mangiano le capre’. Inoltre, a differenza degli umani, i sistemi di IA mantengono lo stesso livello di sicurezza anche quando fanno affermazioni completamente errate.
Particolarmente illuminante è questa riflessione sulle differenze tra errori umani e artificiali:
L'esperienza di vita ci rende abbastanza facile indovinare quando e dove gli umani commetteranno errori.
Gli errori dell'IA, invece, si verificano in momenti apparentemente casuali, senza poter essere circoscritti a particolari ambiti.
L'articolo suggerisce due possibili direzioni di lavoro: sviluppare LLM che commettano errori più ‘umani’ o creare nuovi sistemi di sicurezza specifici per gli errori dell'IA. Gli autori concludono sottolineando l'importanza di limitare l'uso dei sistemi di IA a applicazioni adatte alle loro reali capacità, tenendo sempre presente la natura dei loro possibili errori.
L’articolo - breve e facile anche per i non addetti ai lavori - è un contributo prezioso al dibattito sulla sicurezza dell'IA, che evidenzia come la comprensione delle differenze tra errori umani e artificiali sia fondamentale per poterli usare consapevolmente oltre che per sviluppare sistemi di controllo efficaci.
📚 Consigli di visione: ‘La trasformazione creativa nell'era dell'IA’ di Jamie van Leeuwen
Interessante il discorso tenuto da Jamie van Leeuwen durante un TEDx in Australia in cui esplora la rivoluzione che l'IA sta portando nel mondo delle industrie creative. Van Leeuwen, dopo 15 anni di esperienza come film-maker e fotografo, condivide come un'immagine generata dall'IA abbia cambiato la sua visione sulla creazione artistica e sulle opportunità per i futuri creativi. L'IA non solo supera le limitazioni fisiche tradizionali, ma offre anche strumenti accessibili e veloci, capaci di generare contenuti indistinguibili da quelli realizzati con metodi tradizionali (ce ne ha parlato anche l’artista italiano Diavù nel vocale di LeggeZero #56).
Attraverso la sua esperienza personale, compresa la creazione di un'immagine di una spiaggia all'alba grazie a un generatore di immagini AI, van Leeuwen dimostra come questa tecnologia possa liberare la creatività, rendendola disponibile a tutti. Questo approccio ha provocato discussioni etiche e scetticismo all'interno delle comunità creative, ma ha anche mostrato le potenzialità dell'IA nel fornire un nuovo modo di esprimere sé stessi. L'autore sottolinea che, nonostante l'IA offra potenti strumenti, è la direzione umana e l'abilità narrativa che determinano la qualità e la rilevanza della creazione.
Questo video - che dura poco più di 15 minuti - è una risorsa utile per chi cerca di capire come l’avvento dell'IA stia trasformando il panorama creativo e quali siano le sfide e opportunità future.
💬 Il dibattito sull’IA
Per la prima volta nella storia, è tecnicamente possibile annientare la privacy.
Secondo lo storico di fama mondiale Yuval Noah Harari, l’IA può arrivare dove non sono riusciti neanche i regimi totalitari più organizzati (come l’Unione Sovietica). Se avete letto Nexus e vi è piaciuto (per noi è stato il libro migliore del 2024), non potete perdere l’intervista ad Harari nel podcast di Rich Roll (durata: 1 ora e 37 minuti). Nel corso dell’intervista, lo storico - che parla di IA come ‘intelligenza aliena’ ormai capace di decisioni autonome - evidenzia i suoi potenziali benefici, come in ambito sanitario, ma anche i pericoli, tra cui sorveglianza globale e perdita di controllo. Anche Harari sottolinea l'urgenza di regolamentare l'IA per garantire un futuro sicuro e ‘umano’.
📣 Eventi
È giunto il tempo dell’Intelligenza Artificiale - Webinar, 23.01.2025
AI Regulation Summit - Londra, 27.01.2025
Artificial Intellicenge Action Summit - Parigi, 10-11.02.2025
🙏 Grazie per averci letto!
Per ora è tutto, torniamo la prossima settimana. Se la newsletter ti è piaciuta, commenta o fai girare.